Today, OpenSSL 1.0.2d has been released. Many lines of code have been changed, but most important is a Security Fix that allowed an attacker to bypass certain checks on certificates. The problem is summarized in the changelog of the new release:
Changes between 1.0.2c and 1.0.2d [9 Jul 2015]
*) Alternate chains certificate forgery
During certificate verfification, OpenSSL will attempt to find an alternative certificate chain if the first attempt to build such a chain fails. An error in the implementation of this logic can mean that an attacker could cause certain checks on untrusted certificates to be bypassed, such as the CA flag, enabling them to use a valid leaf certificate to act as a CA and “issue” an invalid certificate.
This issue was reported to OpenSSL by Adam Langley/David Benjamin (Google/BoringSSL).
[Matt Caswell]
How does certificate validation work?
In general, when validating an X.509 certificate (for example when accessing a website using https), the validator has a list of trusted authorities (effectively the list of CAs in your browser), the certificate to validate and possibly also a list of helper certificates that can be used to establish a chain of trust to one of the trusted authorities. Certificate validation is a two step process. At first, a path from the certificate to a trusted authority is established, then this path is verified. There might be more than one path, and should verification fail, another path might be determined and verification is tried again.
How does the attack work?
Fortunately, included in the patch is also an additional test for OpenSSL in crypto/x509/verify_extra_test.c that describes the problem in detail. The scenario outlined here is the following:
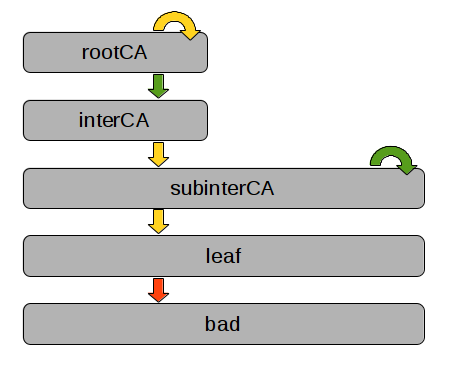
Arrows are certificates, grey boxes denote entities. The two certificates in green are trusted by the verifier. Both subinterCA certificates (the self signed one and the one signed by interCA) share of course the private key. The attacker is in possession of the leaf certificate with the corresponding private key, which is a normal client certificate without CA=true. This scenario might be common for CAs that start independently, and are later on signed by another CA.
When the attacker uses the private key of the leaf certificate to sign another certificate for bad, it should be rejected since the leaf certificate does not have CA=true set. However, OpenSSL fails to reject this certificate properly when the interCA->subinterCA and the subinterCA->leaf certificates are provided as (untrusted) auxiliary certificates.
Who is affected?
Probably anyone who uses client certificate authentication for his webserver. However this is still very uncommon, since username/password authentication is still the most common form of authentication on the web.
Countermeasures
The best countermeasure here is to update OpenSSL to 1.0.2d or a later version. Alternatively (NOT RECOMMENDED) it might be possible to accept only certificates that are known by the server with tools such as stunnel and setting verify=3. Also, such scenarios with multiple paths for a single certificate might be avoided.
